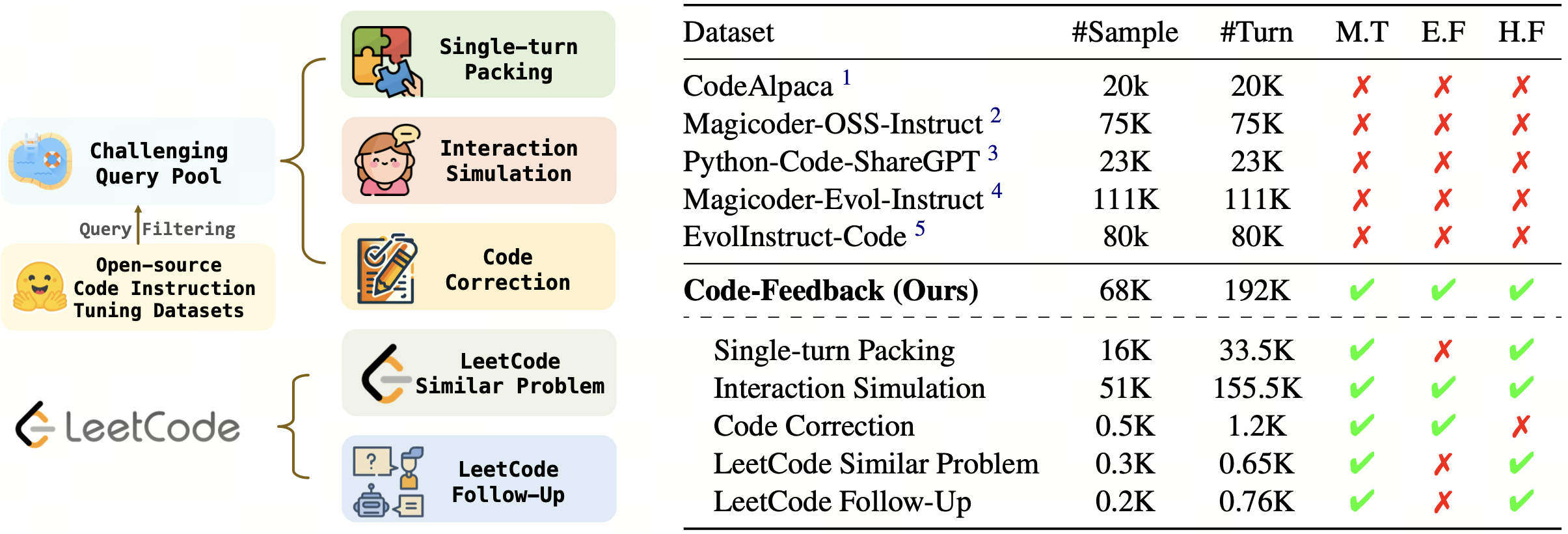
This section outlines the experimental framework for evaluating the performance of OpenCodeInterpreter and its comparison with leading models in both single-turn and multi-turn code generation settings. The study leverages data from the EvalPlus leaderboard, examining OpenCodeInterpreter's performance against benchmarks such as GPT-3.5/4-Turbo, CodeLlama-Python, WizardCoder, Deepseek-Coder, and CodeT5+ across various scales on the HumanEval and MBPP benchmarks and their advanced versions. For multi-turn code generation, the focus shifts to assessing OpenCodeInterpreter's capability in iterative refinement through a two-round limit, considering execution feedback and human feedback scenarios. The experimental setup aims to highlight OpenCodeInterpreter's adaptability and proficiency in code generation, underscored by its achievements in setting new standards in software development tools through iterative feedback and refinement.
`CL': based on CodeLlama; `DS': based on DeepseekCoder. Baseline results are copied from the EvalPlus Leaderboard or replicated by running the official checkpoints.
| Model | Size | Type | Open-source | HumanEval (+) | MBPP (+) | Average (+) | |
|---|---|---|---|---|---|---|---|
| Model | Data | ||||||
| GPT-4 Turbo | - | - | ○ | ○ | 85.4 (81.7) | 83.0 (70.7) | 84.2 (76.2) |
| + Execution Feedback | 88.0 (84.2) | 92.0 (78.2) | 90.0 (81.2) | ||||
| GPT-3.5 Turbo | - | - | ○ | ○ | 72.6 (65.9) | 81.7 (69.4) | 77.2 (67.7) |
| + Execution Feedback | 76.8 (70.7) | 87.0 (73.9) | 81.9 (72.3) | ||||
| Gemini Pro | - | - | ○ | ○ | 63.4 (55.5) | 72.9 (57.9) | 68.2 (56.7) |
| ~7B Scale | |||||||
| StarCoder | 7B | Base | ● | ● | 24.4 (20.7) | 33.1 (28.8) | 28.8 (24.8) |
| CodeT5+ | 6B | Base | ● | ● | 29.3 (23.8) | 51.9 (40.9) | 40.6 (32.4) |
| CodeGen-Mono | 6B | Base | ● | ● | 29.3 (25.6) | 49.9 (42.1) | 39.6 (33.9) |
| Mistral | 7B | Base | ● | ○ | 28.7 (23.2) | 50.1 (40.9) | 39.4 (32.1) |
| OpenChat | 7B | Instruct | ● | ● | 72.0 (67.1) | 62.7 (52.9) | 67.4 (60.0) |
| CodeLlama-Python | 7B | Base | ● | ○ | 37.8 (34.1) | 57.6 (45.4) | 47.7 (39.8) |
| WizardCoder-CL | 7B | Instruct | ○ | ○ | 48.2 (40.9) | 56.6 (47.1) | 52.4 (44.0) |
| Magicoder-CL | 7B | Instruct | ● | ● | 60.4 (55.5) | 64.2 (52.6) | 62.3 (54.1) |
| Magicoders-S-CL | 7B | Instruct | ● | ● | 70.7 (66.5) | 68.4 (56.6) | 69.6 (61.6) |
| OpenCodeInterpreter-CL | 7B | Instruct | ● | ● | 72.6 (67.7) | 66.4 (55.4) | 69.5 (61.6) |
| + Execution Feedback | 75.6 (70.1) | 69.9 (60.7) | 72.8 (65.4) | ||||
| DeepseekCoder | 6.7B | Base | ● | ○ | 47.6 (39.6) | 70.2 (56.6) | 58.9 (48.1) |
| DeepseekCoder-Instruct | 6.7B | Instruct | ● | ○ | 73.8 (70.1) | 73.2 (63.4) | 73.5 (66.8) |
| + Execution Feedback | 80.5 (75.6) | 79.9 (70.4) | 80.2 (73.0) | ||||
| Magicoder-DS | 6.7B | Instruct | ● | ● | 66.5 (60.4) | 75.4 (61.9) | 71.0 (61.2) |
| Magicoder-S-DS | 6.7B | Instruct | ● | ● | 76.8 (70.7) | 75.7 (64.4) | 76.3 (67.6) |
| + Execution Feedback | 77.4 (72.0) | 73.2 (62.4) | 75.3 (67.2) | ||||
| OpenCodeInterpreter-DS | 6.7B | Instruct | ● | ● | 76.2 (72.0) | 73.9 (63.7) | 75.1 (67.9) |
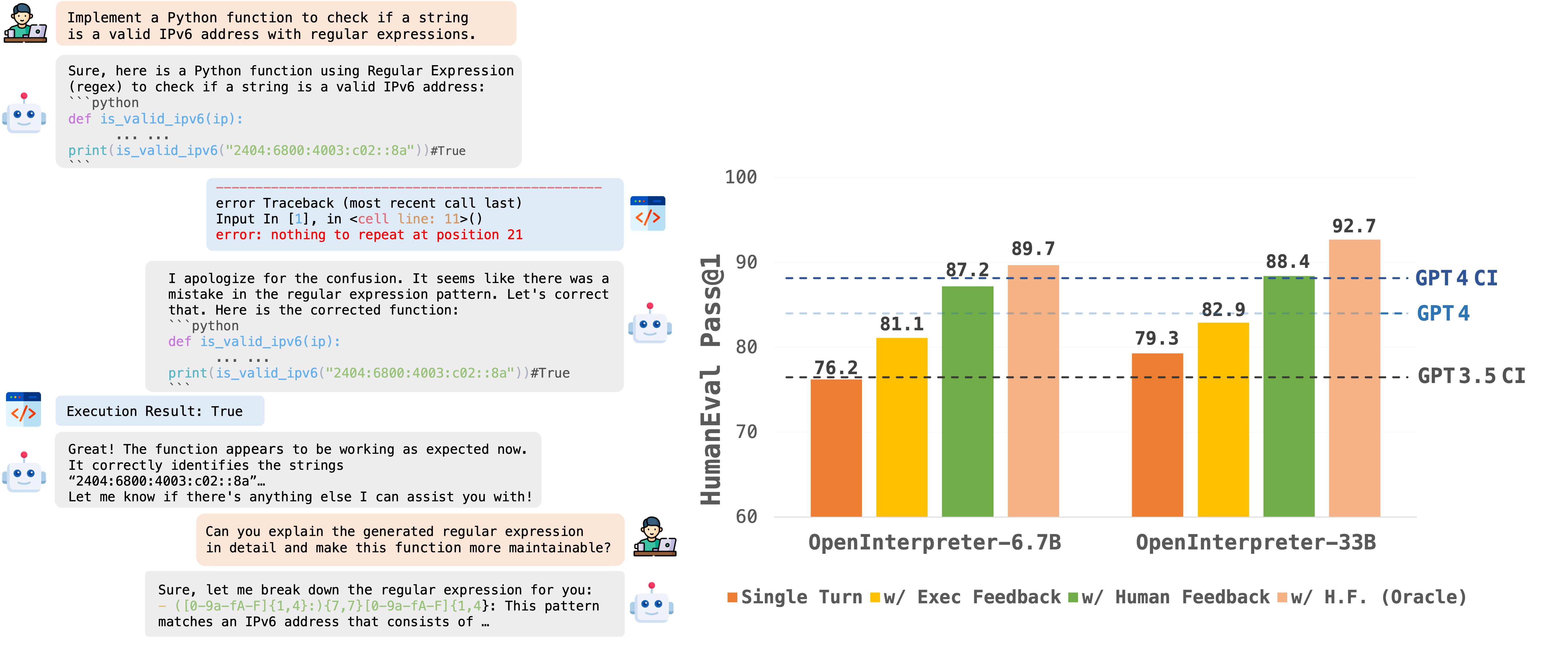
| + Execution Feedback | 81.1 (78.7) | 82.7 (72.4) | 81.9 (75.6) | ||||
| + Synth. Human Feedback | 87.2 (86.6) | 86.2 (74.2) | 86.7 (80.4) | ||||
| + Synth. Human Feedback (Oracle) | 89.7 (86.6) | 87.2 (75.2) | 88.5 (80.9) | ||||
| ~13B Scale | |||||||
| CodeGen-Mono | 16B | Base | ● | ● | 32.9 (27.4) | 52.6 (43.6) | 42.8 (35.5) |
| StarCoder | 15B | Base | ● | ○ | 34.1 (29.3) | 55.1 (46.1) | 44.6 (37.7) |
| CodeT5+ | 16B | Base | ● | ○ | 31.7 (26.2) | 54.6 (44.4) | 43.2 (35.3) |
| CodeLlama-Python | 13B | Base | ● | ○ | 42.7 (36.6) | 61.2 (50.9) | 52.0 (43.8) |
| OpenCodeInterpreter-CL | 13B | Instruct | ● | ● | 77.4 (73.8) | 70.7 (59.2) | 74.1 (66.5) |
| + Execution Feedback | 81.1 (76.8) | 78.2 (67.2) | 79.7 (72.0) | ||||
| ~34B Scale | |||||||
| CodeLlama-Python | 34B | Base | ● | ○ | 51.8 (43.9) | 67.2 (52.9) | 59.5 (48.4) |
| Speechless-CL-v2.0 | 34B | Instruct | ● | ● | 77.4 (71.3) | 72.4 (59.1) | 74.9 (65.2) |
| XwinCoder-CL | 34B | Instruct | ● | ● | 75.6 (67.7) | 76.2 (62.4) | 75.9 (65.1) |
| Phind-CL-v2 | 34B | Instruct | ● | ○ | 71.3 (67.1) | - | - |
| WizardCoder-CL | 34B | Instruct | ● | ○ | 73.2 (64.6) | 73.2 (59.9) | 73.2 (62.3) |
| OpenCodeInterpreter-CL | 34B | Instruct | ● | ● | 78.0 (72.6) | 73.4 (61.4) | 75.7 (67.0) |
| + Execution Feedback | 81.7 (78.7) | 80.2 (67.9) | 81.0 (73.3) | ||||
| DeepSeekCoder | 33B | Base | ● | ○ | 51.2 (44.5) | ||
| DeepSeekCoder-Instruct | 33B | Instruct | ● | ○ | 81.1 (75.0) | 78.7 (66.7) | 79.9 (70.9) |
| + Execution Feedback | 81.1 (76.2) | 82.7 (73.4) | 81.9 (74.8) | ||||
| WizardCoder-V1.1 | 33B | Instruct | ● | ○ | 79.9 (73.2) | 78.9 (66.9) | 79.4 (70.1) |
| + Execution Feedback | 74.4 (69.5) | 79.9 (68.2) | 77.2 (68.9) | ||||
| OpenCodeInterpreter-DS | 33B | Instruct | ● | ● | 79.3 (74.3) | 78.7 (66.4) | 79.0 (70.4) |
| + Execution Feedback | 82.9 (80.5) | 83.5 (72.2) | 83.2 (76.4) | ||||
| + Synth. Human Feedback | 88.4 (86.0) | 87.5 (75.9) | 88.0 (81.0) | ||||
| + Synth. Human Feedback (Oracle) | 92.7 (89.7) | 90.5 (79.5) | 91.6 (84.6) | ||||
| ~70B Scale | |||||||
| CodeLlama-Python | 70B | Base | ● | ○ | 55.5 (50.0) | 65.4 (53.4) | 60.5 (51.7) |
| CodeLlama-Instruct | 70B | Instruct | ● | ○ | 72.0 (65.2) | 75.4 (61.7) | 73.7 (63.5) |
| OpenCodeInterpreter-CL | 70B | Instruct | ● | ● | 76.2 (70.7) | 73.0 (61.9) | 74.6 (66.3) |
| + Execution Feedback | 79.9 (77.4) | 81.5 (69.9) | 80.7 (73.7) | ||||